
This is, hopefully, an in-depth (ELI5) post on how I designed the script. We will use the github repository README as a starting point.
Installation and usage
The premise of the code is to use a combination of pandas and praw to get firstly markdown formatted tables from ESPN and then finally to paste those files into reddit. Then github actions to deploy the code every day, scheduled at given time you can find it on .github/worklows.
There are a requirement files, since this is ran in Spyder[https://www.spyder-ide.org/] for checks it includes the Spyder-necessary packages. You can simply set-up a venv locally and run pip install -r src/requirements. You might need to add pywin32 manually if running locally on a windows machine. Please be aware that this is configured to be ran by github actions and thus it uses load_dotenv() and github secrets. If running locally you might want to set the reddit instance of praw in praw.ini as following the documentation. The script also has four different LUTs, please be aware that if running something similar for a western conference team you’d need to change the LUT_Standings_newRed and LUT_Standings_oldRed.
Further changes based on different subreddits
We use the styles variable to set the different color schemes for the widgets. Please note that the color codes can be easily found when you set manually the widgets on the subreddit. Further, we use a file called restOfSidebar.md found in outputs/ that is the rest of the markdown required for the old reddit setup, please add yours accordingly. Finally, be aware to run locally praw and indentify if your widgets are properly assigned, in our case we have a fixed rules widget which occupies the position widgets.sidebar[0] so we have schedule, roster and standings to be placed at the positions [1], [2], [3] respectively.
Constant updates
In order to keep your repo actions running you need to constantly update the repo. Maximum 3 months without updates are allowed.
Look-up-tables (LUTs)
The LUTs are required to create the links properly. In old-reddit by linking a team in markdown as such [](r/teamSubrredit) the icon of said subreddit will appear which provides a nice look for the schedule and standings as such:
![]()
In new reddit it will highlight this (as an hyperlink) and link directly to other teams subreddit. Because of how ESPN handles standings and schedules in their website you need to define two different LUTs. The examples for r/bostonceltics are below:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
LUT_Standings_newRed = {
'Milwaukee Bucks':'[Bucks](/r/MkeBucks)',
'Boston Celtics':'[Celtics](/r/bostonceltics)',
'Charlotte Hornets':'[Hornets](/r/CharlotteHornets)',
'Cleveland Cavaliers':'[Cavs](/r/clevelandcavs)',
'New York Knicks':'[Knicks](/r/NYKnicks)',
'Washington Wizards':'[Wizards](/r/washingtonwizards)',
'Atlanta Hawks':'[Hawks](/r/AtlantaHawks)',
'Toronto Raptors':'[Raptors](/r/torontoraptors)',
'Chicago Bulls':'[Bulls](/r/chicagobulls)',
'Brooklyn Nets':'[Nets](/r/GoNets)',
'Detroit Pistons':'[Pistons](/r/DetroitPistons)',
'Philadelphia 76ers':'[Philly](/r/sixers)',
'Indiana Pacers':'[Pacers](/r/pacers)',
'Miami Heat':'[Heat](/r/heat)',
'Orlando Magic':'[Magic](/r/OrlandoMagic)'
}
LUT_Standings_oldRed = {
'Milwaukee Bucks':'[](/r/mkebucks) Bucks',
'Boston Celtics':'[](/r/bostonceltics) Celtics',
'Charlotte Hornets':'[](/r/charlottehornets) Hornets',
'Cleveland Cavaliers':'[](/r/clevelandcavs) Cavs',
'New York Knicks':'[](/r/nyknicks) Knicks',
'Washington Wizards':'[](/r/washingtonwizards) Wizards',
'Atlanta Hawks':'[](/r/atlantahawks) Hawks',
'Toronto Raptors':'[](/r/torontoraptors) Raptors',
'Chicago Bulls':'[](/r/chicagobulls) Bulls',
'Brooklyn Nets':'[](/r/gonets) Nets',
'Detroit Pistons':'[](/r/detroitpistons) Pistons',
'Philadelphia 76ers':'[](/r/sixers) Philly',
'Indiana Pacers':'[](/r/pacers) Pacers',
'Miami Heat':'[](/r/heat) Heat',
'Orlando Magic':'[](/r/orlandomagic) Magic'
}
LUT_Teams_newRed = {
'Philadelphia':'[Philly](/r/sixers)',
'Miami':'[Heat](/r/heat)',
'Orlando':'[Magic](/r/OrlandoMagic)',
'Chicago': '[Bulls](/r/chicagobulls)',
'Cleveland':'[Cavs](/r/clevelandcavs)',
'Washington':'[Wizards](/r/washingtonwizards)',
'New York':'[Knicks](/r/NYKnicks)',
'Memphis':'[Memphis](/r/memphisgrizzlies)',
'Detroit':'[Pistons](/r/DetroitPistons)',
'Oklahoma City':'[Thunder](/r/Thunder)',
'Atlanta':'[Hawks](/r/AtlantaHawks)',
'New Orleans':'[Pelicans](/r/NOLAPelicans)',
'Dallas':'[Dallas](/r/Mavericks)',
'Sacramento':'[Kings](/r/kings)',
'Charlotte':'[Hornets](/r/CharlotteHornets)',
'Brooklyn':'[Nets](/r/GoNets)',
'Toronto':'[Raptors](/r/torontoraptors)',
'Phoenix':'[Suns](/r/suns)',
'Golden State':'[Warriors](/r/warriors)',
'LA':'[Clippers](/r/LAClippers)',
'Los Angeles':'[Lakers](/r/lakers)',
'Indiana':'[Pacers](/r/pacers)',
'Milwaukee':'[Bucks](/r/MkeBucks)',
'Houston':'[Houston](/r/rockets)',
'Denver':'[Denver](/r/denvernuggets)',
'San Antonio':'[Spurs](/r/NBASpurs)',
'Portland':'[Blazers](/r/ripcity)',
'Utah':'[Jazz](/r/UtahJazz)',
'Minnesota':'[Wolves](/r/timberwolves)'
}
LUT_Teams_oldRed = {
'Philadelphia':'[](/r/sixers)',
'Miami':'[](/r/heat)',
'Orlando':'[](/r/orlandomagic)',
'Chicago': '[](/r/chicagobulls)',
'Cleveland':'[](/r/clevelandcavs)',
'Washington':'[](/r/washingtonwizards)',
'New York':'[](/r/nyknicks)',
'Memphis':'[](/r/memphisgrizzlies)',
'Detroit':'[](/r/detroitpistons)',
'Oklahoma City':'[](/r/thunder)',
'Atlanta':'[](/r/atlantahawks)',
'New Orleans':'[](/r/nolapelicans)',
'Dallas':'[](/r/mavericks)',
'Sacramento':'[](/r/kings)',
'Charlotte':'[](/r/charlottehornets)',
'Brooklyn':'[](/r/gonets)',
'Toronto':'[](/r/torontoraptors)',
'Phoenix':'[](/r/suns)',
'Golden State':'[](/r/warriors)',
'LA':'[](/r/laclippers)',
'Los Angeles':'[](/r/lakers)',
'Indiana':'[](/r/pacers)',
'Milwaukee':'[](/r/mkebucks)',
'Houston':'[](/r/rockets)',
'Denver':'[](/r/denvernuggets)',
'San Antonio':'[](/r/nbaspurs)',
'Portland':'[](/r/ripcity)',
'Utah':'[](/r/utahjazz)',
'Minnesota':'[](/r/timberwolves)'
}
Used functions
This script uses two defined functions useful for the whole season: remove and remove_parts_of_strings. The fist one is used to remove the number from the players names when looking through the roster, the second is to remove non-sense from the teams names for the standings from the position in the standings to whether the team has clinched playoffs or not. The function check_string is mostly used for the playoff and to clean the roster. In the Celtics case Gallinari hasn’t played all year nor should he, so I manually excluded him. But manually doing it for every player in terms of links and all other things is annoying. So this function serves to check whether a string later on is contained in the string with the players profile link, then we can properly assign the link to the player name in markdown automatically.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
## functions space
def remove(list):
pattern = '[0-9]'
list = [re.sub(pattern, '', i) for i in list]
return list
def remove_parts_of_string(*strings): #generated by ChatGPT
for string in strings:
# Remove all characters before the first uppercase letter
index = [i for i in range(len(string)) if string[i].isupper()][0]
string = string[index:]
# Remove all characters before the first lowercase letter
index = [i for i in range(len(string)) if string[i].islower()][0]
string = string[index-1:]
return(string)
def check_string(string1, string2_series):
string1 = re.sub(r'\W+', '', string1.lower())
string2_series = string2_series.apply(lambda x: re.sub(r'\W+', '', x.lower()))
result_series = string2_series.str.contains(string1)
if result_series.any():
return result_series.idxmax()
else:
return -1 # or any other value that indicates no True value was found
Roster
To pick the desired roster one needs to get the ESPN link. To find this link all you need to do is to go to the team’s ESPN page and tap into the Roster tab. For the Boston Celtics this link looks like this: https://www.espn.com/nba/team/roster/_/name/bos/boston-celtics
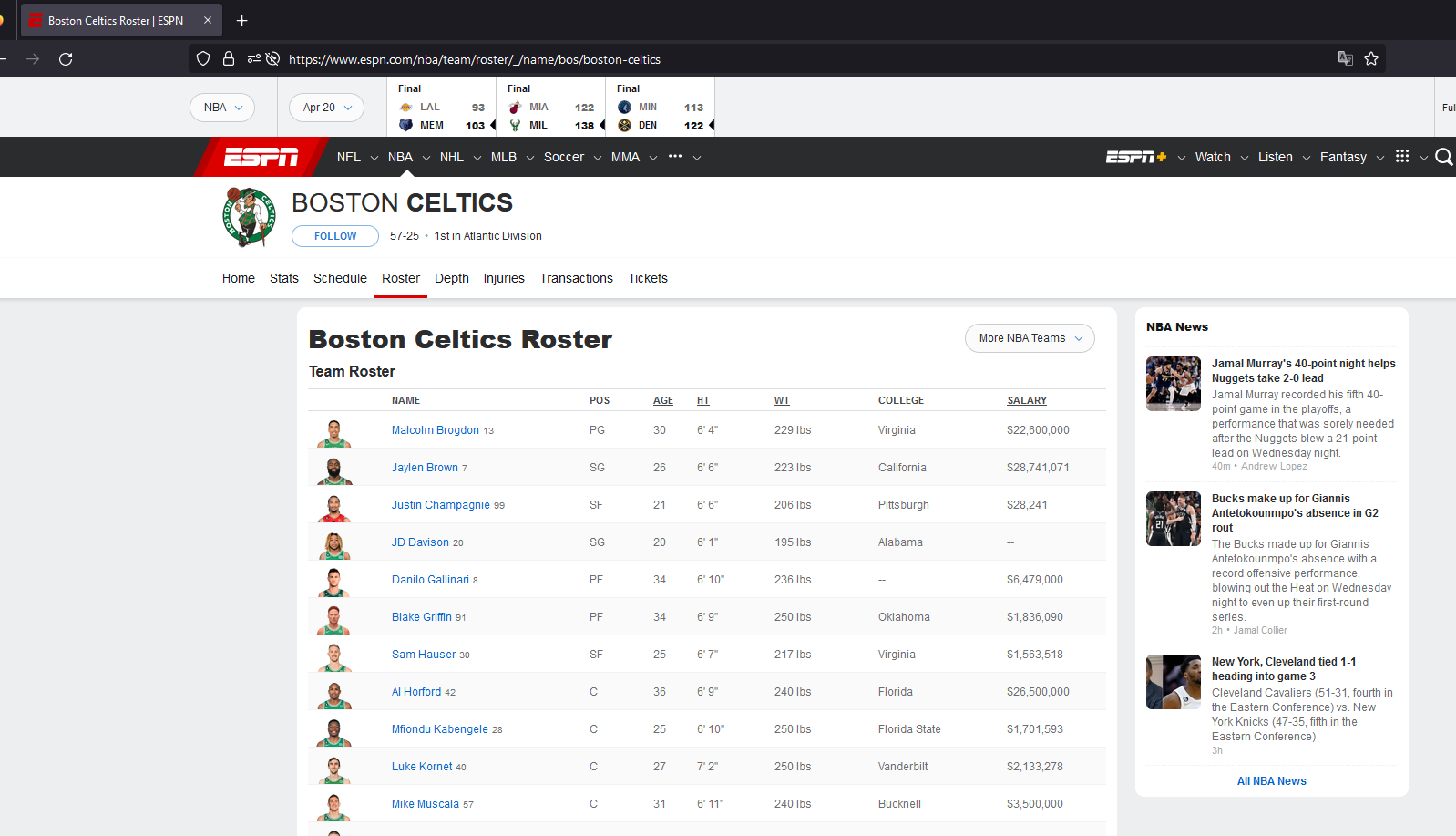
Once we do this we can use pandas to extract the roster itself, we use the positional argument [0] to simply access the dataframe created. Then we create another variable to extract the links to the players profile with table_roster_links_init = pd.read_html(roster_url,extract_links='body')[0] and we extract only the link. Then we create a dictionary to use later to link each player name to its ESPN profile link, once we have re-arranged our table to be as we wish.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
roster_url = 'https://www.espn.com/nba/team/roster/_/name/bos/boston-celtics'
table_roster_init = pd.read_html(roster_url)[0]
table_roster_links_init = pd.read_html(roster_url,extract_links='body')[0]
table_roster_links = table_roster_links_init['Name']
names = []
espn_links = []
for i in range(len(table_roster_links)):
names.append(table_roster_links[i][0])
espn_links.append(str(table_roster_links[i][1]))
names = remove(names)
table_roster_dropped = (table_roster_init.copy())
name_link_dict = {}
for i in range(len(table_roster_links)):
name_link_dict[names[i]] = espn_links[i]
We now re-arrange the players based on its salary. So from highest to lowest salary in the roster. We start by dropping an extra column Unnamed: 0 created with the extraction. Then we start removing all the non-sense from the salary definition such as the $ symbol, -- which is used for two-way players (as they’re paid per game played) and finally the , to create a single long value. We then converrt this value to int and we also assign a nan value to two-way players. We then re-arrange with sort_values the salaries to create our index of the players. The salaries won’t be displayed, so we can remove the six zeros for ease to read the variables. We then finally reset the index of the table. We also remove the first name of the players, to make it cleaner on the reddit page that has limited space (specially in new reddit).
1
2
3
4
5
6
7
8
9
10
11
table_roster_dropped = table_roster_dropped.drop(['Unnamed: 0'], axis=1)
table_roster_dropped['Salary'] = table_roster_dropped['Salary'].str.replace('$', '',regex=True)
table_roster_dropped['Salary'] = table_roster_dropped['Salary'].str.replace('--', '0',regex=True)
table_roster_dropped['Salary'] = table_roster_dropped['Salary'].str.replace(',', '', regex=True)
table_roster_dropped['Salary'] = table_roster_dropped['Salary'].astype(int)
table_roster_dropped['Salary'] = table_roster_dropped['Salary'].replace(0, np.nan)
table_roster_dropped.sort_values(by='Salary', inplace=True, ascending=False)
table_roster_dropped['Salary'] = table_roster_dropped['Salary'].div(1e6).round(decimals=1)
table_roster_dropped['Name'] = table_roster_dropped['Name'].str.replace('\d+', '',regex=True)
table_roster_dropped = table_roster_dropped.reset_index(drop=True)
Now we really create the tables, we start by iterating over the cleaned and re-sorted version of the table to create a first-look dataframe. This serves mostly for debugging and to create a dictionary capable for replacing the names for the names with links. We then go over to create the stats that we will use. We defined as a concise amount of data points per game, FG%, 3P%, rebounds, assists and stocks (steals+blocks). We verify if the player has games this season. Come the post-season you also need to verify if the player hasn’t played an N amount of games or in extreme cases simply remove it completely with an extra verification step (shown after the normal code). We switch the normal name to the hyper-linked name.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
outputRoster = []
for i in range(len(table_roster_dropped)):
if "Gallinari" in table_roster_dropped['Name'][i]:
pass
else:
nameAndLink = '[' + table_roster_dropped['Name'][i].split(' ',1)[1] +']('+name_link_dict[table_roster_dropped['Name'][i]]+')'
tempSalary = str(table_roster_dropped['Salary'][i]) + 'M'
outputRoster.append(
{
'Name':nameAndLink,
'Age':table_roster_dropped['Age'][i],
'Salary': tempSalary
}
)
outputRoster_df = pd.DataFrame(outputRoster)
allStats = []
for index, row in table_roster_dropped.iterrows():
#print(row)
dataread = pd.read_html(name_link_dict[row['Name']])
if len(dataread)>1:
if 'GP' in dataread[2].columns and row['Name'] != "Danilo Gallinari":
allStats.append(
{
'Name':row['Name'],
'PPG':dataread[2]['PTS'][0],
'FG%':dataread[2]['FG%'][0],
'3P%':dataread[2]['3P%'][0],
'RBG': dataread[2]['REB'][0],
'APG': dataread[2]['AST'][0],
'STOCK':(float(dataread[2]['BLK'][0])+float(dataread[2]['STL'][0]))
})
else:
pass
else:
pass
allStats_df = pd.DataFrame(allStats)
for index,row in allStats_df.iterrows():
allStats_df['Name'][index] = outputRoster_df['Name'][check_string(row['Name'], outputRoster_df['Name'])]
allStats_df.to_markdown('outputs/roster.md',stralign='center', numalign='center',index=False)
For playoffs we had to run this due to both Kabengele and Gallo having played in the NBA and playoffs in the past.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
outputRoster = []
for i in range(len(table_roster_dropped)):
if "Gallinari" in table_roster_dropped['Name'][i]:
pass
else:
nameAndLink = '[' + table_roster_dropped['Name'][i].split(' ',1)[1] +']('+name_link_dict[table_roster_dropped['Name'][i]]+')'
tempSalary = str(table_roster_dropped['Salary'][i]) + 'M'
outputRoster.append(
{
'Name':nameAndLink,
'Age':table_roster_dropped['Age'][i],
'Salary': tempSalary
}
)
outputRoster_df = pd.DataFrame(outputRoster)
allStats = []
for index, row in table_roster_dropped.iterrows():
#print(row)
dataread = pd.read_html(name_link_dict[row['Name']])
if len(dataread)>1:
if 'GP' in dataread[2].columns and dataread[2].iloc[1]['GP'] != '-' and dataread[2].iloc[1]['GP'] <28 and row['Name'] != "Danilo Gallinari":
allStats.append(
{
'Name':row['Name'],
'PPG':dataread[2]['PTS'][1],
'FG%':dataread[2]['FG%'][1],
'3P%':dataread[2]['3P%'][1],
'RBG': dataread[2]['REB'][1],
'APG': dataread[2]['AST'][1],
'STOCK':(float(dataread[2]['BLK'][1])+float(dataread[2]['STL'][1]))
})
else:
pass
else:
pass
Schedule
For the schedule the very first thing is to verify the current month as such month = datetime.today().strftime('%b') so everything will be displayed on a monthly basis.